文献阅读笔记-TransNet: Shift Invariant Transformer Network for Side Channel Analysis
文章信息
-
作者:Suvadeep Hajra1,Sayandeep Saha2,Manaar Alam3,Debdeep Mukhopadhyay1 。
-
单位:
- Indian Institute of Technology Kharagpur, Kharagpur, India
- Nanyang Technological University, Singapore
- New York University Abu Dhabi, United Arab Emirates
-
会议: AFRICACRYPT 2022
Note
现有基于深度学习的侧信道攻击均应用 CNN、RNN、MLP 等神经网络模型来代替传统的判别器,基于卷积神经网络模型的侧信道攻击在带有掩码、随机延迟的数据集上表现良好(非线性、平移不变性),然而,已有的工作均基于较小的随机延迟窗口(<=100)的情况下开展。
本文提出将 TN 引入到 SCA 领域,将基于相对位置的多头注意力机制替代原有的归一化层+多头注意力机制,利用 TN 可捕获长距离依赖的特性来对抗较大窗口的随机延迟对策,相较于已有的工作,在大随机延迟窗口的条件下获得了最优结果。
背景知识
Transformer Network(TN)
TODO: 单独一篇文章讲
注意力机制
自注意力机制
https://blog.csdn.net/weixin_43610114/article/details/126684999
Position-wise Feed-Forward Layer (FFN)
位置编码
研究方法
长序列处理
由于掩码对策的影响,组成中间值的每一部分泄露在不同位置的样本点上,这些位置之间的距离可能很远,(TODO:这里单独计算掩码以及明文异或密钥后的信噪比计算出来(ASCADF))。
值得注意的是,本文采用的自注意力机制是在不同的 step 上计算出注意力得分,此特性可以捕获不同距离之间的关联性,对随机延迟窗口较大的场景鲁棒,具体机制如图 1 所示。
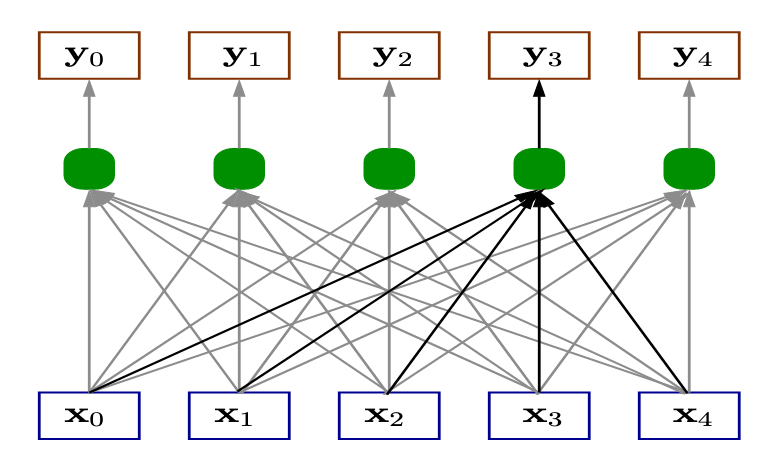
每一个输出得分$\vec{y}$都由不同位置的 $X$叠加通过公式TODO计算得出,以此,模型可以在 share 相距较远的情况下捕获相关的依赖性,从而在随机延迟窗口较大的情况下获得良好的结果。
图 2 展示了 TransNet 的架构,由一个卷积层、平均池化层、RelPositional Multi-Head Attention、PoswissFF、全局平均池化层、FF Layer和 softmax 层构成,损失函数采用交叉熵损失,设置 Adam 作为优化器,采取余弦退火策略来动态调整训练过程中的学习率。
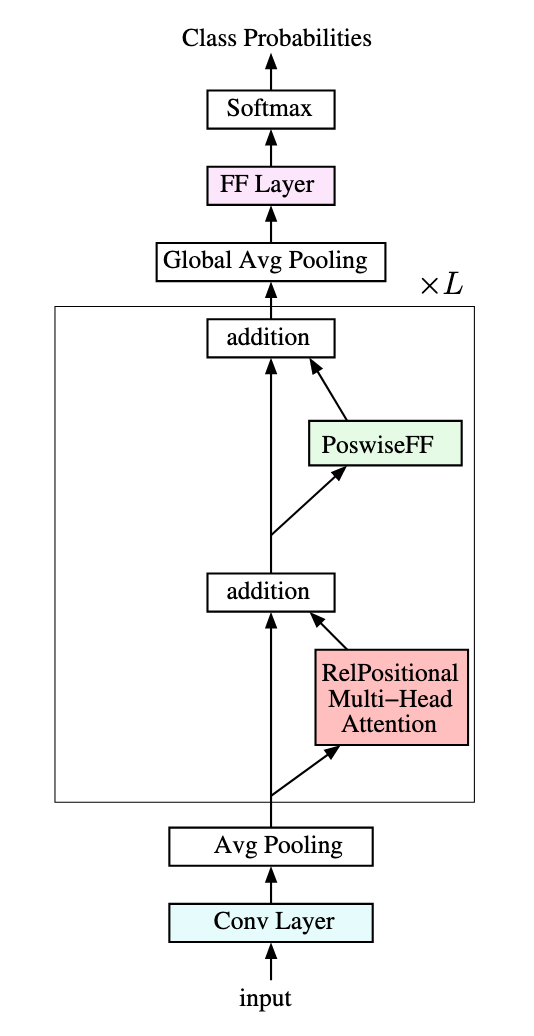
图 2 TransNet 架构图
实验步骤&结果


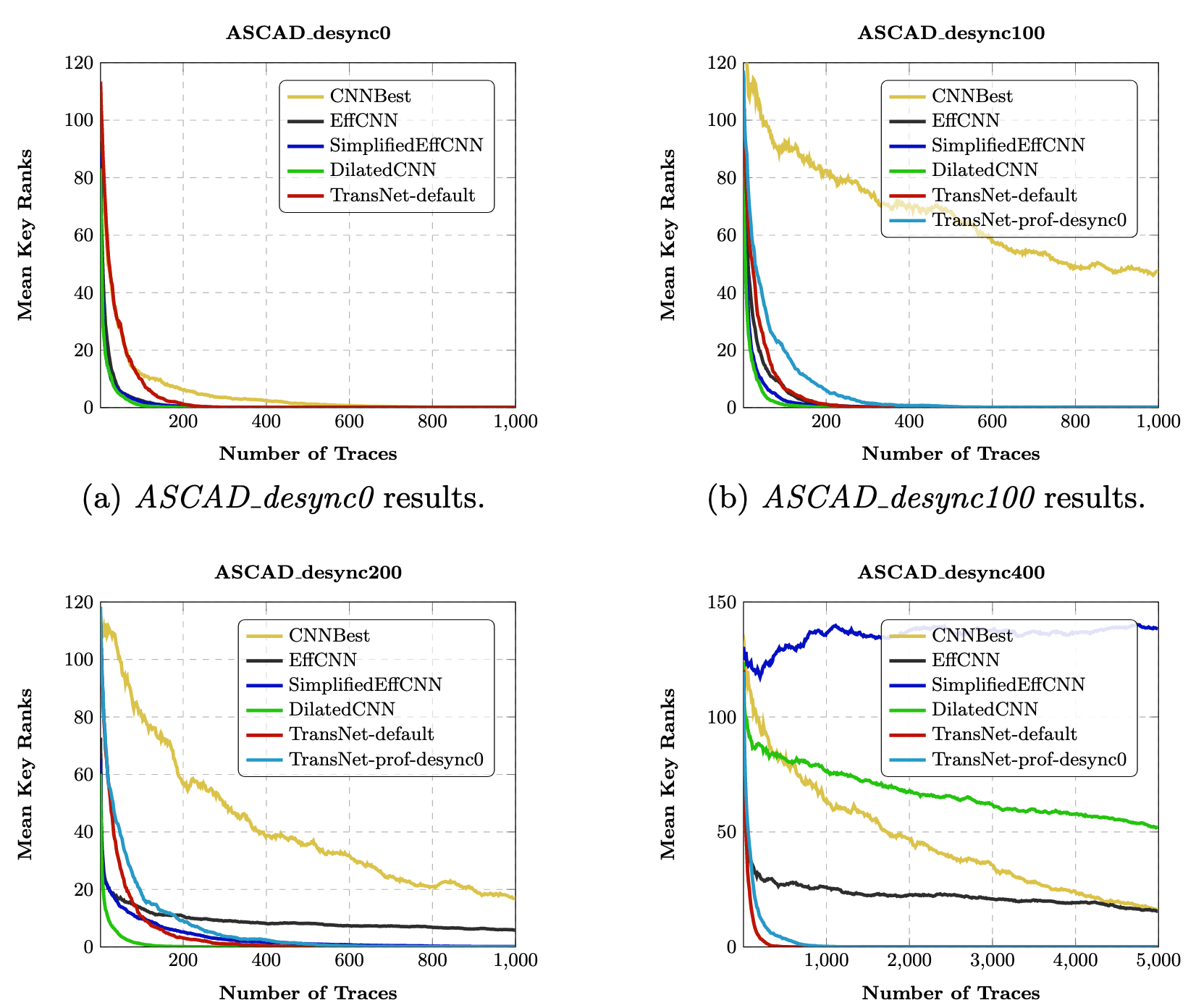




Related Content
- 模板攻击从入门到入土
- 侧信道攻击-信噪比
- 侧信道攻击-皮尔逊相关系数
- 文献阅读笔记-Label Correlation in Deep Learning-Based Side-Channel Analysis
- 基于深度学习的侧信道攻击指北